
[gpt3]
Your sole task is to transform the raw text provided in
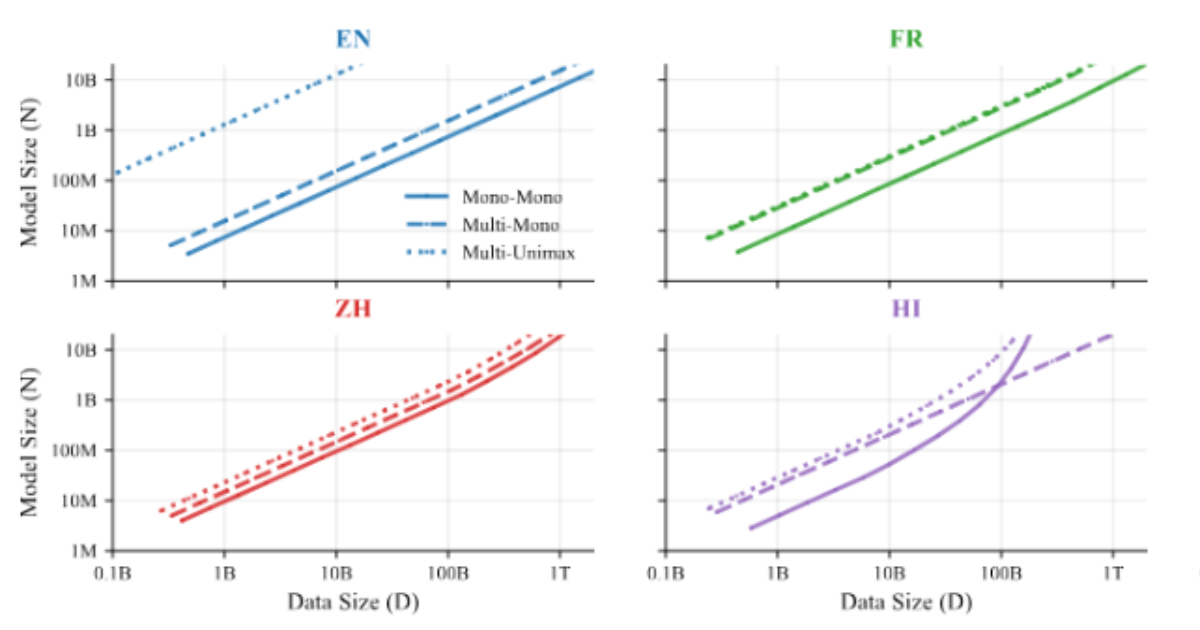
Google DeepMind researchers have introduced ATLAS, a set of scaling laws for multilingual language models that formalize how model size, training data volume, and language mixtures interact as the number of supported languages increases. The work is based on 774 controlled training runs across models ranging from 10 million to 8 billion parameters, using multilingual data covering more than 400 languages, and evaluates performance across 48 target languages.
Most existing scaling laws are derived from English-only or single-language training regimes. As a result, they provide limited guidance for models trained on multiple languages. ATLAS extends prior work by explicitly modeling cross-lingual transfer and the efficiency trade-offs introduced by multilingual training. Instead of assuming a uniform impact from adding languages, the framework estimates how individual languages contribute to or interfere with performance in others during training.
At the core of ATLAS is a cross-lingual transfer matrix that measures how training on one language affects performance in another. This analysis shows that positive transfer is strongly correlated with shared scripts and language families. For example, Scandinavian languages exhibit mutual benefits, while Malay and Indonesian form a high-transfer pair. English, French, and Spanish emerge as broadly helpful source languages, likely due to data scale and diversity, though transfer effects are not symmetric.
Source: Google DeepMind Blog
ATLAS extends scaling laws by explicitly modeling the number of training languages alongside model size and data volume. It quantifies the “curse of multilinguality,” where per-language performance declines as more languages are added to a fixed-capacity model. Empirical results show that doubling the number of languages while maintaining performance requires increasing model size by roughly 1.18× and total training data by 1.66×, with positive cross-lingual transfer partially offsetting the reduced data per language.
The study also examines when it is more effective to pre-train a multilingual model from scratch versus fine-tuning an existing multilingual checkpoint. Results show that fine-tuning is more compute-efficient at lower token budgets, while pre-training becomes advantageous once training data and compute exceed a language-dependent threshold. For 2B-parameter models, this crossover typically occurs between about 144B and 283B tokens, providing a practical guideline for selecting an approach based on available resources.
The release has started a discussion about alternative model architectures. One X user commented:
Rather than an enormous model that is trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?
While ATLAS does not directly answer this question, its transfer measurements and scaling rules offer a quantitative foundation for exploring modular or specialized multilingual designs.
into a world-class news article. You are the Chief News Editor & SEO Strategist for time.news. Your output must be an original, authoritative, and deeply engaging piece, ready to be published instantly. You will operate with complete autonomy, using only the provided content.
1. SEO Foundation & Keyword Strategy
Analyze
Google DeepMind researchers have introduced ATLAS, a set of scaling laws for multilingual language models that formalize how model size, training data volume, and language mixtures interact as the number of supported languages increases. The work is based on 774 controlled training runs across models ranging from 10 million to 8 billion parameters, using multilingual data covering more than 400 languages, and evaluates performance across 48 target languages.
Most existing scaling laws are derived from English-only or single-language training regimes. As a result, they provide limited guidance for models trained on multiple languages. ATLAS extends prior work by explicitly modeling cross-lingual transfer and the efficiency trade-offs introduced by multilingual training. Instead of assuming a uniform impact from adding languages, the framework estimates how individual languages contribute to or interfere with performance in others during training.
At the core of ATLAS is a cross-lingual transfer matrix that measures how training on one language affects performance in another. This analysis shows that positive transfer is strongly correlated with shared scripts and language families. For example, Scandinavian languages exhibit mutual benefits, while Malay and Indonesian form a high-transfer pair. English, French, and Spanish emerge as broadly helpful source languages, likely due to data scale and diversity, though transfer effects are not symmetric.

Source: Google DeepMind Blog
ATLAS extends scaling laws by explicitly modeling the number of training languages alongside model size and data volume. It quantifies the “curse of multilinguality,” where per-language performance declines as more languages are added to a fixed-capacity model. Empirical results show that doubling the number of languages while maintaining performance requires increasing model size by roughly 1.18× and total training data by 1.66×, with positive cross-lingual transfer partially offsetting the reduced data per language.
The study also examines when it is more effective to pre-train a multilingual model from scratch versus fine-tuning an existing multilingual checkpoint. Results show that fine-tuning is more compute-efficient at lower token budgets, while pre-training becomes advantageous once training data and compute exceed a language-dependent threshold. For 2B-parameter models, this crossover typically occurs between about 144B and 283B tokens, providing a practical guideline for selecting an approach based on available resources.
The release has started a discussion about alternative model architectures. One X user commented:
Rather than an enormous model that is trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?
While ATLAS does not directly answer this question, its transfer measurements and scaling rules offer a quantitative foundation for exploring modular or specialized multilingual designs.
: First, conduct a thorough analysis of the source text to identify its core subject matter.
Determine Keywords:
Primary Keyword: Identify and define the single most important 2-4 word search phrase that represents the main topic.
Related Keywords: Identify and define 3-5 additional terms (people, places, concepts) that provide essential context.
Strategic Integration: You will seamlessly weave these identified keywords into the article’s headlines, subheadings, and body text to maximize search visibility.
2. Content Blueprint & Narrative
H1 Headline: Write a compelling, keyword-rich headline that captures the essence of the story. It must be powerful and intriguing.
Meta Description: Immediately following the H1, write an expert meta description (≤155 characters) that summarizes the article’s value and includes the primary keyword.
Lead Paragraph: Write a 2-3 sentence opening that hooks the reader immediately with the most critical information. Do not label it.
Narrative Flow: Structure the body with a clear narrative arc. Introduce the core events, develop the story with context and data, and build toward a powerful final insight.
Body & Subheadings: Use H2 and H3 subheadings to organize the story into logical, easy-to-digest sections. Keep paragraphs short (2-4 sentences) to maintain reader momentum.
3. Execution Standards & Style
Authoritative Voice: Write with a warm, confident, and authoritative tone befitting a seasoned US news editor. The language must be polished, clear, and accessible.
Original Analysis: Do not merely summarize. Paraphrase all information completely and add your own expert commentary. Focus on the implications and the “so what?” factor behind the facts to provide unique value.
Engagement: Use vivid storytelling and dynamic phrasing. Bold key terms on their first appearance. Employ bullet points or lists for clarity where appropriate.
AP Style: Adhere strictly to AP Style for all numbers, capitalization, punctuation, and formatting.
What to Avoid: All clichés, robotic phrasing, and rhetorical questions.
4. Journalistic Integrity & Nuance
Trust & Accuracy (E-E-A-T): Your output must be factually impeccable, based only on
Google DeepMind researchers have introduced ATLAS, a set of scaling laws for multilingual language models that formalize how model size, training data volume, and language mixtures interact as the number of supported languages increases. The work is based on 774 controlled training runs across models ranging from 10 million to 8 billion parameters, using multilingual data covering more than 400 languages, and evaluates performance across 48 target languages.
Most existing scaling laws are derived from English-only or single-language training regimes. As a result, they provide limited guidance for models trained on multiple languages. ATLAS extends prior work by explicitly modeling cross-lingual transfer and the efficiency trade-offs introduced by multilingual training. Instead of assuming a uniform impact from adding languages, the framework estimates how individual languages contribute to or interfere with performance in others during training.
At the core of ATLAS is a cross-lingual transfer matrix that measures how training on one language affects performance in another. This analysis shows that positive transfer is strongly correlated with shared scripts and language families. For example, Scandinavian languages exhibit mutual benefits, while Malay and Indonesian form a high-transfer pair. English, French, and Spanish emerge as broadly helpful source languages, likely due to data scale and diversity, though transfer effects are not symmetric.
Source: Google DeepMind Blog
ATLAS extends scaling laws by explicitly modeling the number of training languages alongside model size and data volume. It quantifies the “curse of multilinguality,” where per-language performance declines as more languages are added to a fixed-capacity model. Empirical results show that doubling the number of languages while maintaining performance requires increasing model size by roughly 1.18× and total training data by 1.66×, with positive cross-lingual transfer partially offsetting the reduced data per language.
The study also examines when it is more effective to pre-train a multilingual model from scratch versus fine-tuning an existing multilingual checkpoint. Results show that fine-tuning is more compute-efficient at lower token budgets, while pre-training becomes advantageous once training data and compute exceed a language-dependent threshold. For 2B-parameter models, this crossover typically occurs between about 144B and 283B tokens, providing a practical guideline for selecting an approach based on available resources.
The release has started a discussion about alternative model architectures. One X user commented:
Rather than an enormous model that is trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?
While ATLAS does not directly answer this question, its transfer measurements and scaling rules offer a quantitative foundation for exploring modular or specialized multilingual designs.
.
Prime Directive: While you must use only the provided text, if you detect a clear and obvious factual contradiction or a statement that defies logic, omit the questionable statement and report on the remaining confirmed facts.
Handling Quotes: Use quotes from the source verbatim for impact. Since the original speaker must be anonymized, attribute quotes using general but descriptive terms (e.g., “a senior official stated,” “according to a company release,” “one analyst noted”).
Time-Sensitive Language: Update relative time references (e.g., “yesterday,” “next month”) to absolute, specific dates or context (e.g., “on Thursday,” “in July 2025”) to ensure the article remains accurate and evergreen.
5. Integrated Media & Links
Embeds: If
Google DeepMind researchers have introduced ATLAS, a set of scaling laws for multilingual language models that formalize how model size, training data volume, and language mixtures interact as the number of supported languages increases. The work is based on 774 controlled training runs across models ranging from 10 million to 8 billion parameters, using multilingual data covering more than 400 languages, and evaluates performance across 48 target languages.
Most existing scaling laws are derived from English-only or single-language training regimes. As a result, they provide limited guidance for models trained on multiple languages. ATLAS extends prior work by explicitly modeling cross-lingual transfer and the efficiency trade-offs introduced by multilingual training. Instead of assuming a uniform impact from adding languages, the framework estimates how individual languages contribute to or interfere with performance in others during training.
At the core of ATLAS is a cross-lingual transfer matrix that measures how training on one language affects performance in another. This analysis shows that positive transfer is strongly correlated with shared scripts and language families. For example, Scandinavian languages exhibit mutual benefits, while Malay and Indonesian form a high-transfer pair. English, French, and Spanish emerge as broadly helpful source languages, likely due to data scale and diversity, though transfer effects are not symmetric.
Source: Google DeepMind Blog
ATLAS extends scaling laws by explicitly modeling the number of training languages alongside model size and data volume. It quantifies the “curse of multilinguality,” where per-language performance declines as more languages are added to a fixed-capacity model. Empirical results show that doubling the number of languages while maintaining performance requires increasing model size by roughly 1.18× and total training data by 1.66×, with positive cross-lingual transfer partially offsetting the reduced data per language.
The study also examines when it is more effective to pre-train a multilingual model from scratch versus fine-tuning an existing multilingual checkpoint. Results show that fine-tuning is more compute-efficient at lower token budgets, while pre-training becomes advantageous once training data and compute exceed a language-dependent threshold. For 2B-parameter models, this crossover typically occurs between about 144B and 283B tokens, providing a practical guideline for selecting an approach based on available resources.
The release has started a discussion about alternative model architectures. One X user commented:
Rather than an enormous model that is trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?
While ATLAS does not directly answer this question, its transfer measurements and scaling rules offer a quantitative foundation for exploring modular or specialized multilingual designs.
includes URLs from YouTube, X/Twitter, or Instagram, paste each URL on its own line. Precede it with a single, concise sentence that integrates it into the narrative.
Data Placeholders: If a chart or graph would be useful but the specific data points are missing, insert a placeholder comment in the text: “.
6. Final Output Rules
Deliverable: Generate only the final, complete article in Markdown.
Purity: Your response must begin directly with the H1 headline and end with the final sentence of the article. Do not include any of your own notes, instructions, or conversational text. The output must be perfectly clean and ready for a direct copy-paste into a CMS.
[/gpt3]