

NVIDIA has officially transitioned the ownership of its Dynamic Resource Allocation (DRA) Driver for GPUs to the Cloud Native Computing Foundation (CNCF), moving a critical piece of AI infrastructure from vendor-governed software to a community-owned open source project. The announcement, made during KubeCon Europe in Amsterdam, aims to standardize how high-performance GPU resources are orchestrated within Kubernetes, the industry-standard platform for managing containerized applications.
For engineers and enterprises, this shift addresses a persistent bottleneck in AI scaling. While Kubernetes has long been the bedrock for deploying applications, the specific demands of AI workloads—which require precise, high-performance access to hardware—have historically required significant manual effort to manage. By donating the DRA driver to the Cloud Native Computing Foundation, NVIDIA is allowing a broader circle of global experts to contribute to and refine the code, ensuring the technology evolves alongside the rapidly shifting cloud-native landscape.
The move is part of a larger strategy to advance open source AI by reducing the friction between hardware capabilities and software orchestration. This donation ensures that the driver is no longer tied solely to NVIDIA’s internal roadmap but is instead governed by a vendor-neutral organization, making high-performance GPU orchestration more seamless and accessible for the global developer community.
Solving the GPU Orchestration Challenge
In the early days of GPU acceleration in the cloud, managing hardware was often a rigid process. Developers frequently struggled with “bin-packing” workloads—trying to fit AI models into available GPU memory without wasting expensive computing power. The NVIDIA DRA Driver for GPUs changes this dynamic by allowing for more fluid, precise, and dynamic resource requests.
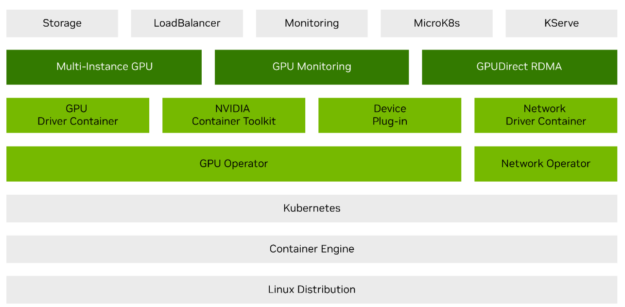
The driver introduces several key technical improvements that directly impact how AI models are trained and deployed:
- Granular Resource Sharing: Through support for NVIDIA Multi-Process Service (MPS) and Multi-Instance GPU (MIG) technologies, the driver enables smarter sharing of GPU resources, ensuring that multiple workloads can coexist on a single chip without compromising performance.
- Interconnect Scalability: The driver provides native support for NVIDIA Multi-Node NVlink. This is a critical requirement for training massive Large Language Models (LLMs) on next-generation infrastructure, such as NVIDIA Grace Blackwell systems, where thousands of GPUs must communicate with minimal latency.
- On-the-Fly Reconfiguration: Rather than restarting entire clusters to change hardware settings, developers can now dynamically reconfigure how resources are allocated to suit the immediate needs of a specific application.
- Precision Requests: Users can now make fine-tuned requests for specific memory settings or interconnect arrangements, moving away from the “one size fits all” approach to GPU allocation.
Strengthening Security through Confidential Computing
Beyond resource allocation, NVIDIA is addressing the growing concern over data privacy in AI. In collaboration with the CNCF’s Confidential Containers community, the company has introduced GPU support for Kata Containers. Kata Containers are lightweight virtual machines that provide a stronger layer of isolation than standard containers.
By extending hardware acceleration into these isolated environments, organizations can implement confidential computing. This ensures that sensitive data remains protected even while being processed by a GPU, a necessity for industries like healthcare and finance where data sovereignty and privacy are non-negotiable. This integration allows AI workloads to run with enhanced protection, effectively separating workloads to prevent unauthorized access or data leakage.
An Ecosystem of Industry Collaboration
The transition of the DRA Driver is not a solitary effort. NVIDIA is working with a consortium of cloud and infrastructure leaders to ensure these features are integrated across the most common enterprise environments. This collaborative group includes Amazon Web Services, Google Cloud, Microsoft, Red Hat, Broadcom, Canonical, Nutanix, and SUSE.
The impact of this collaboration extends beyond commercial enterprises into the realm of fundamental science. At CERN, where researchers analyze petabytes of data to uncover the secrets of the universe, the move toward community-driven innovation is viewed as a catalyst for discovery. Ricardo Rocha, lead of platforms infrastructure at CERN, noted that the donation strengthens the ecosystem researchers rely on to process data across both traditional scientific computing and emerging machine learning workloads.
The industry-wide shift toward standardization is echoed by Red Hat’s Chris Wright, chief technology officer and senior vice president of global engineering, who stated that open source will be at the core of every successful enterprise AI strategy by bringing standardization to the high-performance components that fuel production workloads.
Expanding the Open Source Portfolio
The DRA Driver donation is one piece of a larger open-source push from NVIDIA. Recently, the company has released several other projects aimed at improving the stability and security of AI clusters:
| Project | Primary Function | Key Feature |
|---|---|---|
| NVSentinel | GPU Fault Remediation | Automated system for detecting and fixing GPU errors. |
| AI Cluster Runtime | Agentic AI Framework | Standardized runtime for managing AI agent behaviors. |
| NemoClaw | Reference Stack | Open framework for deploying AI models. |
| OpenShell | Secure Runtime | Programmable policy controls for autonomous agents. |
| KAI Scheduler | Workload Scheduling | High-performance AI scheduler (now a CNCF Sandbox project). |
Further expanding this ecosystem is the release of Grove, an open source Kubernetes API designed for orchestrating AI workloads on GPU clusters. Grove allows developers to define complex inference systems as a single declarative resource, which is currently being integrated with the llm-d inference stack to encourage wider adoption across the Kubernetes community.
What So for the Future of AI Infrastructure
By moving these tools into the CNCF ecosystem, the industry is moving away from “siloed” hardware management. When the tools used to manage GPUs are open and community-governed, it reduces vendor lock-in and allows for faster iteration. If a developer at a startup finds a more efficient way to allocate memory, that improvement can be contributed back to the project, benefiting every organization using the driver.
The next major milestone for this ecosystem will be the continued evolution of the KAI Scheduler within the CNCF Sandbox, where it will undergo further community testing and refinement to determine its readiness for a full graduation to a CNCF project. This process will likely dictate how the next generation of AI-native clouds are built.
We want to hear from the developer community: How will community ownership of GPU drivers change your infrastructure strategy? Share your thoughts in the comments below.